О различиях между блокирующими и неблокирующими присваиваниями
Вскоре после начала курса студенты сталкиваются с понятиями "блокирующего" и "неблокирующего" присваивания. Часто объяснения преподавателей по этой теме сопровождаются словами "последовательный" и "параллельный", а также предлагается просто запомнить [1, стр. 2]:
- при описании последовательностной логики (регистров) используйте неблокирующее присваивание;
- при описании комбинационной логики используйте блокирующее присваивание.
Давайте разберемся что это за присваивания и почему необходимо руководствоваться этими правилами.
Начать придется издалека. Несмотря на то, что SystemVerilog является языком описания аппаратуры, он так же является и языком для верификации описанной аппаратуры (слово Verilog является объединением двух слов: verification и logic [2, стр. 24]). Для целей верификации в языке выделено целое подмножество конструкций, которые не могут быть использованы для описания аппаратуры — так называемое "несинтезируемое подмножество языка SystemVerilog". Разумеется, часть языка, которая может быть использована для описания аппаратуры ("синтезируемое подмножество языка SystemVerilog") тоже может использоваться в верификации.
Давайте для начала разберемся в том, как будут использоваться операторы присваивания при программном моделировании (так называемой симуляции) — одном из инструментов верификации. Разобравшись в поведении операторов во время симуляции, будет куда проще объяснить результат использования операторов при синтезе цифровой схемы.
Введем пару сокращений для удобства дальнейшего повествования:
- под
LHS(left hand side) мы будем подразумевать "выражение, которому присваивают"; - под
RHS(right hand side) мы будем подразумевать "выражение, которое присваивают".
В выражении a = b+c, a является LHS, b+c является RHS.
Существует два вида присваиваний: непрерывное и процедурное.
module example_1(
input logic a, b
output logic c, d
);
// непрерывное присваивание
assign c = a + b;
// процедурное присваивание
always_comb begin
d = a + b;
end
endmodule
Листинг 1. Пример непрерывного и процедурного присваивания.
С непрерывным присваиванием вы знакомитесь в самом начале — это оператор assign. Непрерывное присваивание постоянно следит за RHS этого оператора, и каждый раз, когда любая часть этого выражения меняет своё значение, производит пересчёт значения RHS, а затем сразу же передает это значение LHS. Если мы произведем assign a = b+c, то каждый раз, когда будет меняться значение b или c, будет пересчитываться результат их суммы, который сразу же будет присвоен выражению a.
Непрерывное присваивание может быть использовано только вне программных блоков.
Под "программными блоками" подразумеваются блоки always (всех типов) и initial. Есть и другие программные блоки, но в рамках данного курса лабораторных работ вы с ними не столкнетесь. Вообще говоря, синтаксис языка SystemVerilog допускает использование оператора assign внутри программного блока (так называемое "процедурное непрерывное присваивание") [2, стр. 256], однако в рамках данного курса не существует ни одной ситуации, когда это может потребоваться и со 100% вероятностью будет ошибочно.
В отличие от непрерывного присваивания, процедурное присваивание может быть использовано только в программных блоках (процедурное присваивание в общем-то и является присваиванием, произошедшим в программном блоке).
С точки зрения моделирования (не описания аппаратуры), программный блок — это программа (в привычном вам понимании парадигмы программирования), исполняющаяся в отдельном процессе. Программные блоки исполняются независимо друг от друга по определенным событиям.
Блоки initial (их может быть много) исполняются в момент начала моделирования. Блоки always исполняются по событиям, указанным в списке чувствительности:
always @(posedge clk)будет исполняться каждый раз когда произойдет положительный фронтclk;always @(a,b,c)будет исполняться каждый раз, когда изменится значение любого из сигналовa,b,c;always @(*)будет исполняться каждый раз, когда изменится состояние любой составляющей любогоRHSв этом блоке (когда изменится хоть что-то, от чего зависит любое выражение слева от оператора присваивания в этом блоке).
Похожие правила применимы и к остальным блокам always: always_comb, always_ff, always_latch (с некоторыми оговорками, не имеющими значения в рамках данного повествования).
Под независимостью исполнения подразумевается то, что порядок исполнения блоков не зависит от очередности, в которой они были описаны. Более того, исполнение одного блока может быть приостановлено, чтобы исполнить другой блок.
А вот выражения внутри отдельного программного блока (с точки зрения моделирования) исполняются последовательно. И вот тут на сцену выходят два типа процедурного присваивания: блокирующее и неблокирующее.
Блокирующее присваивание (оператор =) блокирует исполнение дальнейших выражений до завершения вычисления RHS и присвоения вычисленного результата LHS (иными словами, это привычное вам присваивание из мира программирования, там все работает точно так же).
Неблокирующее присваивание (оператор <=) производит вычисление RHS, запоминает его, и откладывает присваивание вычисленного значения, позволяя выполняться остальным выражениям до завершения присваивания LHS.
Рассмотрим пример, представленный на рис. 1.

Рисунок 1. Пример цепочки блокирующих присваиваний.
- Сперва вычисляется
RHSпервого присваивания программного блока — константа5. - Затем, вычисленное значение записывается в LHS первого присваивания — сигнал
aстановится равным5. - Далее вычисляется
RHSследующего присваивания —a, которое к этому моменту уже равно5. - Поскольку вычисленное
RHSравняется5,LHSвторого присваивания (b) тоже становится равным5. - Аналогичным образом
cтоже становится равным5.
Обратите внимание, что все это произошло в нулевой момент времени. На временной диаграмме Vivado просто отобразится, что все сигналы одновременно стали равны 5, однако с точки зрения симулятора это было не так. Другие симуляторы (например QuestaSim) позволяют настроить временную диаграмму таким образом, чтобы отображались все переходы между присваиваниями.
Посмотрим, как работает аналогичная цепочка неблокирующих присваиваний. Чтобы иллюстрация была более наглядной, предположим, что перед присваиваниями был исполнен какой-то код, который привел a в состояние 3, b в 2, c в 7.

Рисунок 2. Пример цепочки неблокирующих присваиваний.
- Сперва вычисляется значение
RHSпервого присваивания (5). Присваивание этого значения откладывается на потом. - Затем вычисляется значение
RHSвторого присваивания. Посколькуaеще не присвоили значение5, результатомRHSстановится текущее значениеa— 3. Присваивание этого значения сигналуbоткладывается на потом. - Аналогичным образом вычисляется
RHSтретьего присваивания (2). Присваивание этого значения также откладывается на потом.
Так называемое "потом" наступает, когда завершается вычисление RHS всех неблокирующих присваиваний и завершение присвоений всех блокирующих присваиваний (однако "потом" все равно происходит в тот же момент времени, обратите внимание на значение времени на рис. 2). В стандарте SystemVerilog этот момент называется NBA-region (сокр. от "Non-Blocking Assignment region") [2, стр. 64]. Выполнение отложенных присваиваний происходит в том же порядке, в котором они шли в программном блоке. Подробнее о том как, работает событийная симуляция (event based simulation) в SystemVerilog, вы можете прочесть в стандарте IEEE 1800-2023 (раздел 4). Стандарт доступен бесплатно всем желающим по программе "IEEE GET Program".
Таким образом, если LHS блокирующего присваивания используется в качестве операнда RHS любого другого последующего присваивания, это выражение будет иметь уже обновленное значение, что очень похоже на "последовательное вычисление".
С другой стороны значение, присвоенное LHS значение с помощью неблокирующего присваивания, не может использоваться в качестве операнда RHS последующих присваиваний, что создает иллюзию "параллельного вычисления" (см. рис. 3).

Рисунок 3. Иллюстрация блокирующих и неблокирующих присваиваний.
Теперь, понимая как работают присваивания с точки зрения моделирования, посмотрим на то, во что могут синтезироваться подобные операторы.
Начнем с непрерывного присваивания. Оно превращается в провод, передающий данные от RHS к LHS. При этом вы должны следить за тем, что и чему вы присваиваете (не путайте местами RHS и LHS).
То, во что синтезируются блокирующие и неблокирующие присваивания зависит от описываемой логики, поэтому давайте разберём несколько примеров.
Начнем с исходного примера c цепочкой блокирующих присваиваний, только теперь перепишем его в синтезируемом виде, сохранив изначальную идею.
module example_2(
input logic clk,
input logic [31:0] in,
output logic [31:0] out
);
logic [31:0] a, b, c;
always_ff @(posedge clk) begin
a = in;
b = a;
c = b;
end
assign out = c;
endmodule
Листинг 2. Пример описания модуля, использующего цепочку блокирующих присваиваний.
Если вы уже знакомы с содержимым документа о том, как описывать регистры, подумайте: какой будет результат синтеза у этой схемы?
Давайте "прочитаем" эту схему. Мы видим модуль, с входом in, выходом out и тактирующим синхроимпульсом clk. Также мы видим три сигнала a, b, c, которые описываются в блоке always_ff, предназначенном для описания регистров. Значение in по цепочке этих регистров передается до регистра c, выход которого подключен к выходу out.
Похоже, что здесь был описан сдвиговый регистр, представленный на рис. 4.

Рисунок 4. Трехразрядный сдвиговый регистр.
Давайте откроем цифровую схему, сгенерированную Vivado и убедимся в наших выводах.
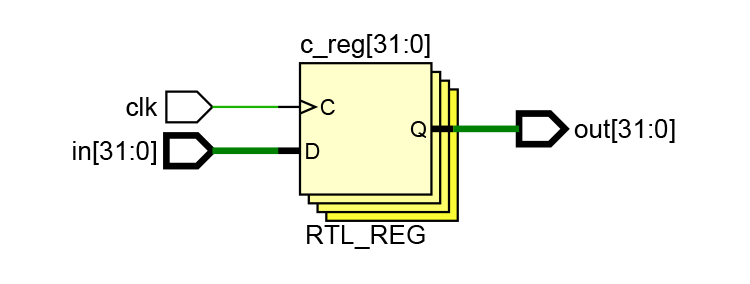
Рисунок 5. Схема, сгенерированная Vivado по описанию из Листинга 2.
Произошло что-то странное. Вместо трех регистров Vivado создал только один и судя по названию — это последний регистр c. Почему это произошло?
Изучим внимательней поведение цепочки блокирующих присваиваний, представленное на рис. 1.
Каждое последующее присваивание ожидало, пока не выполнится предыдущее, таким образом, RHS первого присваивания (5) сразу же распространился по всем регистрам. Моделируя Листинг 2, мы получим поведение, когда на вход каждого регистра будет подаваться сигнал in.
Таким образом на самом деле, мы должны были изобразить нашу схему как на рис. 6.

Рисунок 6. Схема, описанная Листингом 2.
Но почему тогда на схеме Vivado не осталось регистров a и b? Посмотрим на них внимательней. Их выходы ни на что не влияют, они ни к чему не подключены. А значит эти регистры не имеют никакого смысла и, если их убрать, ничего не изменится.
При генерации схемы, Vivado вывел в Tcl Console следующие предупреждения:
WARNING: [Synth 8-6014] Unused sequential element a_reg was removed. [example_1.sv:10]
WARNING: [Synth 8-6014] Unused sequential element b_reg was removed. [example_1.sv:11]
Vivado обнаружил, что регистры a и b ни на что не влияют и удалил их со схемы.
Если вы используете Vivado 2023.1 и новее, вы можете обнаруживать подобные предупреждения более удобным способом — посредством линтера, который можно вызвать из вкладки RTL ANALYSIS окна Flow Navigator.

Рисунок 7. Пример вызова линтера.
Давайте заменим в Листинге 2 блокирующие присваивания на неблокирующие. Напоминаем, что оператор неблокирующего присваивания записывается как <=.
module example_3(
input logic clk,
input logic [31:0] in,
output logic [31:0] out
);
logic [31:0] a,b,c;
always_ff @(posedge clk) begin
a <= in;
b <= a;
c <= b;
end
assign out = c;
endmodule
Листинг 3. Пример описания модуля, использующего цепочку неблокирующих присваиваний.
Посмотрим, какую схему сгенерирует Vivado в этот раз.
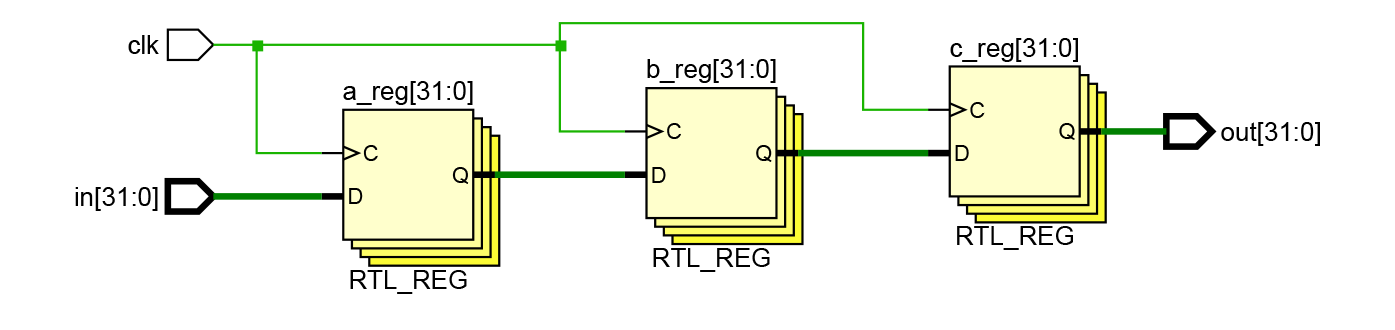
Рисунок 8. Схема, сгенерированная Vivado по описанию из Листинга 3.
Вряд ли полученный результат стал для вас неожиданным сюжетным поворотом, но давайте разберемся, почему в этот раз сгенерировалась схема, аналогичная представленной на рис. 4.
Для этого обратимся к примеру, представленному на рис. 2. В данном примере неблокирующего присваивания сперва вычислялись значения всех RHS (запоминались значения выходов всех регистров) и только потом происходило присваивание новых значений. Подобное поведение аналогично поведению сдвиговых регистров.
Слово "поведение" было выделено дважды неспроста. Описание схем, которое мы сделали называется "поведенческим описанием схемы".
Можно ли реализовать сдвиговый регистр, используя блокирующие присваивания? Конечно. Например, можно поменять порядок присваиваний как в Листинге 4.
module example_4(
input logic clk,
input logic [31:0] in,
output logic [31:0] out
);
logic [31:0] a,b,c;
always_ff @(posedge clk) begin
c = b;
b = a;
a = in;
end
assign out = c;
endmodule
Листинг 4. Цепочка блокирующих присваиваний в порядке, обратном приведенному в Листинге 2.
В этом случае, линтер не сообщит ни о каких ошибках, а Vivado сгенерирует схему, аналогичную рис. 8
Так произошло, поскольку мы разорвали зависимость значений RHS последующих присваиваний от значений LHS предыдущих (поведение, которое демонстрировала цепочка неблокирующих присваиваний с самого начала). Однако данное решение является скорее хаком, чем примером хорошего проектирования. По сути, мы просто подстроили код, описанный с помощью блокирующих присваиваний таким образом, чтоб он вел себя как код, использующий неблокирующие присваивания.
Важно отметить, что при использовании неблокирующих присваиваний, их порядок вообще не имеет значения с точки зрения синтеза.
Давайте разнесем логику работы каждого регистра по отдельным блокам always.
module example_5(
input logic clk,
input logic [31:0] in,
output logic [31:0] out
);
logic [31:0] a,b,c;
always_ff @(posedge clk) begin
a = in;
end
always_ff @(posedge clk) begin
b = a;
end
always_ff @(posedge clk) begin
c = b;
end
assign out = c;
endmodule
Листинг 5. Сдвиговый регистр, описанный через блокирующие присваивания в отдельных блоках always.
Сгенерированная в Vivado схема будет аналогична рис. 8. Но давайте попробуем промоделировать работу этой схемы, подавая случайные воздействия на вход in.

Рисунок 9. Симуляция модуля, описанного Листингом 5.
Выглядит как-то не по "сдвигово-регистерски". В чем же дело?
Как уже упоминалось ранее, программные блоки (коими являются блоки always) исполняются во время моделирования независимо друг от друга в недетерминированном стандартом порядке. На практике это означает, что сперва может исполниться второй блок, потом третий, а потом первый — либо в любом другом порядке. Разработчик не может (и не должен) рассчитывать на порядок блоков always при описании схемы.
Конкретно в данной ситуации, симулятор воспроизвел блоки ровно в том порядке, в котором они были описаны. Сперва a получил значение in, потом b получил обновленное значение a, затем c получил обновленное значение b.
Поскольку поведение недетерминировано, нельзя однозначно сказать, какую схему должен был воспроизвести синтезатор. В данной ситуации, он воспроизвел схему которую мы хотели получить, но моделирование того же самого модуля демонстрирует поведение вовсе не этой схемы.
Если заменить порядок always подобно тому, как мы изменили порядок в Листинге 4, результат на временной диаграмме совпадет с поведением сдвигового регистра.

Рисунок 10. Моделирование поведения сдвигового регистра.
Однако, как уже объяснялось ранее, вы не можете рассчитывать на такой результат. Сегодня симулятор смоделировал поведение одним образом — завтра он смоделирует этот же код (в котором не изменилась ни одна строка) по-другому, и будет по-прежнему работать в соответствии со стандартом.
Для того, чтобы получить детерминированный результат, вам необходимо снова воспользоваться неблокирующим присваиванием, поскольку и в этом случае порядок исполнения блоков always не влияет на результат присваиваний — сначала вычисляются значения RHS всех неблокирующих присваиваний всех программных блоков, и только потом происходит присваивание этих значений LHS.
Рассмотрим еще один пример того, как различие в присваиваниях приведет к описанию двух различных схем:
module example_6(
input logic clk,
input logic a, b, c,
output logic d
);
logic temp;
always_ff @(posedge clk) begin
temp = a | b;
d = c & temp;
end
endmodule
Листинг 6. Пример цепочки блокирующих присваиваний с комбинационной логикой.
Остановитесь на минуту и подумайте, схему с каким поведением описывает Листинг 6?
Как вы могли догадаться, данный листинг описывает схему с одним регистром d, на вход которого подается результат комбинационной логики c & (a | b), поскольку сперва в temp попадает результат a | b и только после этого вычисляется значение c & temp.
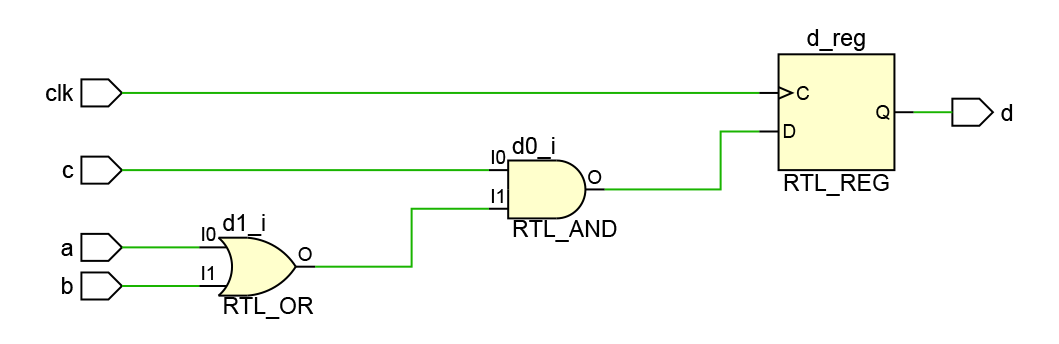
Рисунок 11. Схема, сгенерированная Vivado по описанию из Листинга 6.
Попробуйте догадаться о том, что произойдет, если снова заменить блокирующие присваивания на неблокирующие?
Результат изменится следующим образом.
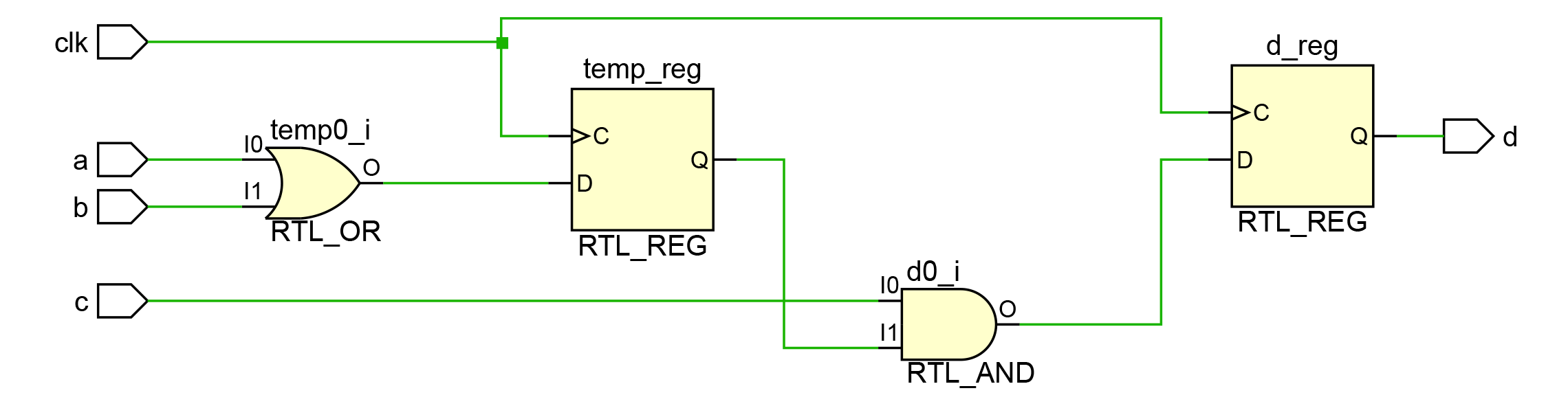
Рисунок 12. Схема, сгенерированная Vivado по описанию из Листинга 6 после замены блокирующих присваиваний на неблокирующие.
Из прочтённого может сложиться впечатление, будто бы авторы хотят показать, что блокирующее присваивание — это плохо, а неблокирующее — хорошо, однако это не так. Это просто два похожих инструмента, работающих разными способами, о которых должен знать профессионал, использующий эти инструменты.
Одно и тоже описание, использующее разные типы присваиваний может привести к синтезу разных схем.
Рассмотрим предыдущий пример еще раз. Нельзя сказать, что одна схема лучше другой — это просто две разные схемы и то, какая из них вам нужна зависит только от вашей задачи.
Однако нельзя не заметить, что при использовании блокирующего присваивания, мы "теряли" регистры. Более того, моделирование неблокирующих присваиваний ближе всего по поведению приближено к моделированию регистровой логики [1, стр. 14].
Пока что мы рассматривали только синхронные схемы (схемы, работающие по тактовому синхроимпульсу).
Рассмотрим зависимость от типа присваивания в комбинационных схемах. Для этого возьмем предыдущий пример, и уберем тактирующий синхроимпульс.
module example_7(
input logic a, b, c,
output logic d
);
logic temp;
always_comb begin
temp = a | b;
d = c & temp;
end
endmodule
Листинг 7. Пример цепочки блокирующих присваиваний в комбинационной схеме.
Обратите внимание на то, что
always_ffпоменялся наalways_comb.
Как вы думаете, какая схема будет сгенерирована по описанию, представленному в листинге 7, и что произойдет с этой схемой, если заменить в нем все блокирующие присваивания на неблокирующие?
Вас может это удивить, но в обоих случаях будет сгенерирована схема, представленная на рис. 13.
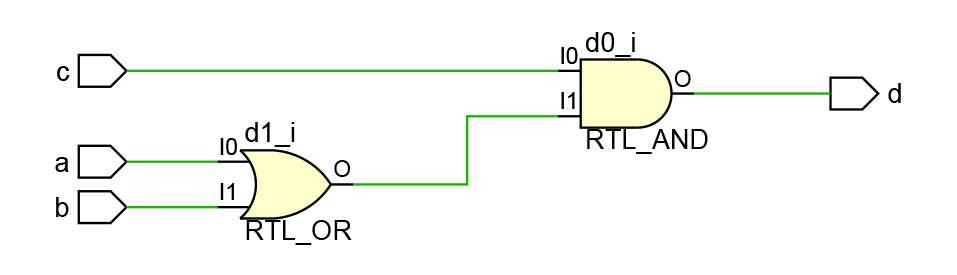
Рисунок 13. Схема, сгенерированная Vivado по описанию из Листинга 7.
Девочка остолбенела. У неё возникло отчётливое чувство какой-то ужасной несправедливости по отношению к ней. Гарри Поттер был грязным, отвратительным обманщиком и лжецом. Но во время игры все его ответы были верными. [Элиезер Юдковский / Гарри Поттер и методы рационального мышления]
На протяжении всего документа вам рассказывали, что использование блокирующих присваиваний приведет к изменению поведения и синтезу другой схемы, а теперь сами же приводят пример, где схема остается точно такой же!
Давайте разберемся по порядку, что же произошло.
Все дело в изменении блока always. Когда мы использовали always_ff @(posedge clk), этот программный блок исполнялся только один раз за такт.
Теперь, когда мы стали использовать блок always_comb, правила игры изменились. Нет, принцип работы блокирующих и неблокирующих присваиваний остался тем же самым. Изменилось только то, сколько раз будет вызван данный блок.
Начнем со схемы, построенной по описанию, использующему блокирующее присваивание. В общем-то, тут у вас не должно было возникнуть вопросов, логика ровно та же, что была и при построении схемы по Листингу 6 (рис. 11), только без выходного регистра. Что логично, ведь мы убрали из описания тактирующий сигнал.
Вопрос в том, почему это вдруг схема, построенная после замены блокирующих присваиваний на неблокирующие ведет себя точно так же?
Рассмотрим рис. 14.

Рисунок 14. Моделирование цепочки присваиваний в комбинационном блоке always.
Комбинационный блок always начинает исполняться каждый раз, когда операнд любого RHS этого блока меняет своё значение.
Изначально, блок always начал исполняться, когда операнды a, b и c приняли значение 1, 0 и 1 соответственно. В этот момент (поскольку присваивание неблокирующее), вычисляются значения RHS для присваивания сигналам temp и d. Новое значение temp будет 1, но пока что этого не произошло, и temp все ещё в состоянии x, поэтому новым значением d все ещё будет x.
После происходит присваивание вычисленных значений сигналам temp и d.
Однако temp является операндом RHS в выражении d = c & temp, поэтому блок always запускается еще один раз в этот же момент времени (в примере это 5ns). Поскольку значения a и b не менялись, значение RHS первого выражения останется прежним. А вот значение temp уже иное, поэтому RHS второго выражения станет 1.
После повторного присваивания сигналы temp и d примут установившееся значение. Поскольку ни один из операндов RHS—выражений больше не изменил своего значения, блок always больше не вызывается.
Подобное поведение можно сравнить с переходным процессом в комбинационной схеме.
Обратите внимание, поведение схем описанных при разных типах присваивания слегка различаются. При блокирующем присваивании все сигналы приняли установившиеся значения за один проход блока always, при неблокирующем потребовалось несколько проходов. Однако с точки зрения пользователя, читающего временную диаграмму, в обоих ситуациях сигналы изменили свое значение мгновенно.
Поэтому несмотря на различия в типах присваиваний схемы получились одинаковыми.
Получается что для комбинационной логики нет разницы между блокирующим и неблокирующим присваиванием, после переходных процессов результат будет одинаковым?
И да, и нет. С точки зрения синтеза схемы так и есть. Однако есть нюанс в случае моделирования схемы. Поведение комбинационной логики лучше моделирует блокирующее присваивание[1, стр. 14].
Итоги главы
Подведем итоги прочитанному:
- Блокирующее присваивание блокирует выполнение остальных операций до завершения текущего присваивания. Оно подобно обычному присваиванию в парадигме программирования.
- Неблокирующее присваивание сперва вычисляет
RHS, давая исполниться остальным операциям до самого присваивания.
В связи с особенностями поведения блокирующего и неблокирующего присваивания, выведены следующие две максимы:
- при описании последовательностной логики (регистров) используйте неблокирующее присваивание;
- при описании комбинационной логики используйте блокирующее присваивание.
Кроме того, существуют следующие рекомендации и требования[1, стр. 5]:
- При описании как последовательностной логики, так и комбинационной в одном блоке
alwaysиспользуйте неблокирующее присваивание. - Не смешивайте в одном блоке блокирующие и неблокирующие присваивания — стандарт допускает подобное описание, но оно затрудняет его чтение. Представьте, что, читая описание схемы, вам бы постоянно приходилось держать в голове, какие присваивания уже произошли, а какие только произойдут, чтобы понять как эта схема работает.
- Не смешивайте блокирующие и неблокирующие присваивания для одного и того же сигнала — стандарт это запрещает (для блоков
always_ff,always_comb,always_latch).